Feature Squeezing
Detecting Adversarial Examples in Deep Neural Networks
Although deep neural networks (DNNs) have achieved great success in many computer vision tasks, recent studies have shown they are vulnerable to adversarial examples. Such examples, typically generated by adding small but purposeful distortions, can frequently fool DNN models. Previous studies to defend against adversarial examples mostly focused on refining the DNN models. They have either shown limited success or suffer from expensive computation. We propose a new strategy, feature squeezing, that can be used to harden DNN models by detecting adversarial examples. Feature squeezing reduces the search space available to an adversary by coalescing samples that correspond to many different feature vectors in the original space into a single sample.

By comparing a DNN model’s prediction on the original input with that on the squeezed input, feature squeezing detects adversarial examples with high accuracy and few false positives. If the original and squeezed examples produce substantially different outputs from the model, the input is likely to be adversarial. By measuring the disagreement among predictions and selecting a threshold value, our system outputs the correct prediction for legitimate examples and rejects adversarial inputs.
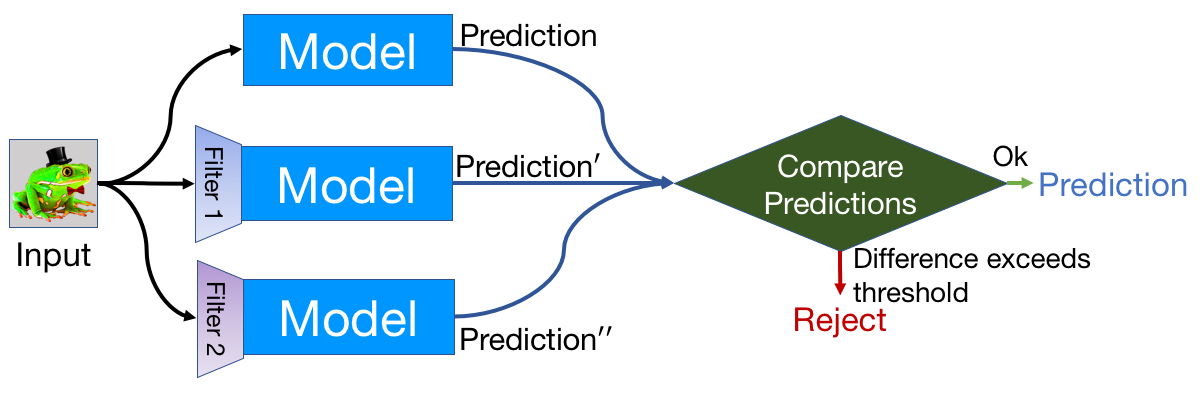
So far, we have explored two instances of feature squeezing: reducing the color bit depth of each pixel and smoothing using a spatial filter. These strategies are straightforward, inexpensive, and complementary to defensive methods that operate on the underlying model, such as adversarial training.
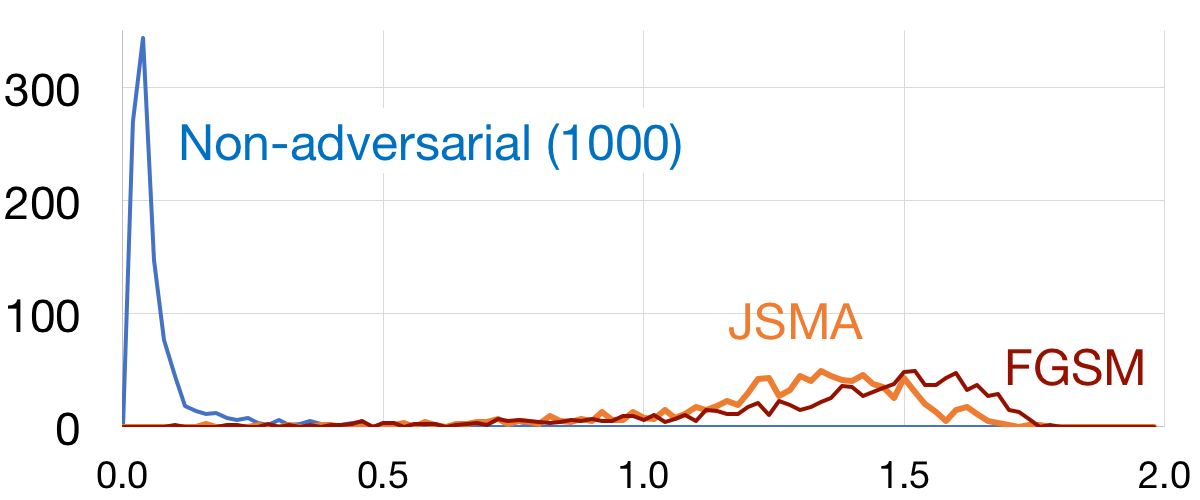
The figure shows the histogram of the L1 scores on the MNIST dataset between the original and squeezed sample, for 1000 non-adversarial examples as well as 1000 adversarial examples generated using both the Fast Gradient Sign Method and the Jacobian-based Saliency Map Approach. Over the full MNIST testing set, the detection accuracy is 99.74% (only 22 out of 5000 fast positives).
Paper
Weilin Xu, David Evans, Yanjun Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. 2018 Network and Distributed System Security Symposium. 18-21 February, San Diego, California. Full paper (15 pages): [PDF]
Code
http://evademl.org/zoo/ (includes all the code needed to reproduce the experiments in the paper)
Team
Weilin Xu (Lead PhD Student)
Yanjun Qi (Facutly Co-Advisor)
David Evans (Faculty Co-Advisor)